
Aug 22, 2022
Online Redo Log- Files-1
Every Oracle database has at least two online redo log file groups. Each redo log group consists of one or more redo log members (redo is managed in groups of members). The individual redo log file members of these groups are true mirror images of each other.
These online redo log files are fixed in size and are used in a circular fashion. Oracle will write to log file group 1, and when it gets to the end of this set of files, it will switch to log file group 2 and overwrite the contents of those files from start to end.
When it has filled log file group 2, it will switch back to log file group 1 (assuming we have only two redo log file groups; if we have three, it would, of course, proceed to the third group). This is shown in Figure 3-4.
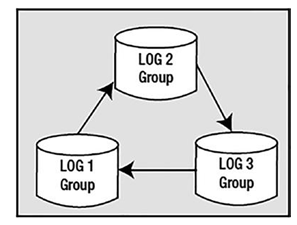
Figure 3-4. Writing to log file groups
The act of switching from one log file group to another is called a log switch. It is important to note that a log switch may cause a temporary “pause” in a poorly configured database. Since the redo logs are used to recover transactions in the event of a failure, we must be certain we won’t need the contents of a redo log file before we are able to use it. If Oracle isn’t sure that it won’t need the contents of a log file, it will suspend operations in the database momentarily and make sure that the data in the cache that this redo “protects” is safely written (checkpointed) onto disk. Once Oracle is sure of that, processing will resume and the redo file will be reused.
We’ve just started to talk about a key database concept: checkpointing. To understand how online redo logs are used, you’ll need to know something about checkpointing, how the database buffer cache works, and what a process called databaseblock writer (DBWn) does. Thedatabase buffer cache and DBWn are covered in more detail later on, but we’llskip ahead a little anyway and touch on them now.
Thedatabase buffer cache is where database blocks are stored temporarily. This isa structure in Oracle’s SGA. As blocks are read, they are stored in this cache, hopefully so we won’t have to physically reread them later.
The buffer cache is first and foremost a performance tuning device. It exists solely to make the very slow process of physical I/O appear to be much faster than it is.
When we modify a block by updating a row on it, these modifications are done in memory to the blocks in the buffer cache. Enough information to redo or to replay this modification is stored in the redo log buffer, another SGA data structure.
When we COMMIT our modifications, making them permanent, Oracle does not go to all of the blocks we modified in the SGA and write them to disk. Rather, it just writes the contents of the redo log buffer out to the online redo logs.
As long as that modified block is in the buffer cache and not on disk, we need the contents of that online redo log in case the database fails. If, at the instant after we committed, the power was turned off, the database buffer cache would be wiped out. If this happens, the only record of our change is in that redo log file.
Upon restart of the database, Oracle will actually replay our transaction, modifying the block again in the same way we did and committing it for us. So, as long as that modified block is cached and not written to disk, we can’t reuse (overwrite) that redo log file.
This is where DBWn comes into play. This Oracle background process is responsible for making space in the buffer cache when it fills up and, more important, for performing checkpoints. A checkpoint is the writing of dirty (modified) blocks from the buffer cache to disk.
Oracle does this in the background for us. Many things can cause a checkpoint to occur, the most common being a redo log switch. As we filled up log file 1 and switched to log file 2, Oracle initiated a checkpoint.
At this point, DBWn started writing to disk all of the dirty blocks that are protected by log file group 1. Until DBWn flushes all of these blocks protected by that log file, Oracle can’t reuse (overwrite) it. If we attempt to use it before DBWn has finished its checkpoint, we’ll get a message like this in our database’s ALERT log: …
Thread 1 cannot allocate new log, sequence 16 Checkpoint not complete Current log# 3 seq# 15 mem# 0: /opt/oracle/oradata/CDB/redo03.log…
More Details