Nov 22, 2022
Control Files- Files
Control files are fairly small files (usually megabytes in size) that contain a directory of the other files Oracle needs.
The parameter file tells the instance where the control files are, and the control files tell the instance where the database and online redo log files are. You can view the location of the control files via the following:
SQL> show parameter control_files
NAME TYPE VALUE
control_files string /opt/oracle/oradata/CDB/
control01.ctl, /opt/oracle/oradata/C
DB/control02.ctl
The control files also tell Oracle other things, such as information about checkpoints that have taken place, the name of the database (which should match the db_name parameter in the parameter file), the timestamp of the database as it was created, an archive redo log history (this can make a control file large in some cases), RMAN information, and so on.
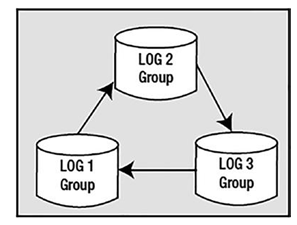
Control files should be multiplexed either by hardware (RAID) or by Oracle when RAID or mirroring is not available. More than one copy should exist, and the copies should be stored on separate disks to avoid losing them in case you have a disk failure. It is not fatal to lose your control files—it just makes recovery that much harder.
Control files are something a developer will probably never have to actually deal with. To a DBA, they are an important part of the database, but to a software developer they are not really relevant.
Redo Log Files
Redo log files are crucial to the Oracle database. These are the transaction logs for the database. They are generally used only for recovery purposes, but they can be used for the following as well:
•\ Instance recovery after a system crash
•\ Media recovery after a datafile restore from backup
•\ Standby database processing
•\ Input into GoldenGate—redo log mining processes for information sharing (a fancy way of saying replication)
•\ Allow administrators to inspect historical database transactions through the Oracle LogMiner utility
Their main purpose in life is to be used in the event of an instance or media failure or as a method of maintaining a standby database for failover. If the power goes off on your database machine, causing an instance failure, Oracle will use the online redo logs to restore the system to exactly the point it was at immediately prior to the power outage. If your disk drive containing your datafile fails permanently, Oracle will use archived redo logs, as well as online redo logs, to recover a backup of that drive to the correct point in time. Additionally, if you “accidentally” drop a table or remove some critical information and commit that operation, you can restore a backup and have Oracle restore it to the point just before the accident using these online and archived redo log files.
Virtually every operation you perform in Oracle generates some amount of redo to be written to the online redo log files. When you insert a row into a table, the end result of that insert is written to the redo logs. When you delete a row, the fact that you deleted that row is written. When you drop a table, the effects of that drop are written to the redo log. The data from the table you dropped is not written; however, the recursive SQL that Oracle performs to drop the table does generate redo. For example, Oracle will delete a row from the SYS.OBJ$ table (and other internal dictionary objects), and this will generate redo, and if various modes of supplemental logging are enabled, the actual DROP TABLE statement will be written into the redo log stream.
Some operations may be performed in a mode that generates as little redo as possible. For example, I can create an index with the NOLOGGING attribute. This means that the initial creation of the index data will not be logged, but any recursive SQL Oracle performed on my behalf will be. For example, the insert of a row into SYS. OBJ$ representing the existence of the index will be logged, as will all subsequent modifications of the index using SQL inserts, updates, and deletes. But the initial writing of the index structure to disk will not be logged.
I’ve referred to two types of redo log file: online and archived. We’ll take a look at each in the sections that follow. In Chapter 9, we’ll take another look at redo in conjunction with undo segments, to see what impact they have on you as a developer. For now, we’ll just concentrate on what they are and what their purpose is.
More Details